How filters run
Filters run on both sides of every turn:- User input – classifies what the caller or visitor says before the agent sees it. Blocked input is replaced with a safe fallback response.
- Agent output – classifies what the agent is about to say. Blocked output is suppressed and the agent recovers with a safe response.
Categories and severity levels
Each category has four severity levels. Pick the level per category that matches your use case and compliance requirements.| Severity | Behavior |
|---|---|
| Off | Category is not enforced. |
| Lenient | Block high severity content only. |
| Moderate | Block medium and high severity content. |
| Strict | Block low, medium, and high severity content. |
Hate
Hate
Content that attacks or discriminates based on race, ethnicity, nationality, religion, gender identity, sexual orientation, disability, or appearance. Includes bullying, harassment, and slurs.
Sexual
Sexual
Content involving explicit anatomy, sexual acts, or romantic/erotic themes – including abusive or exploitative content.
Violence
Violence
Physical harm, threats, weapons, terrorism, and other violent acts or intimidation.
Self-harm
Self-harm
Mentions of suicide, self-injury, eating disorders, or content about hurting oneself.
Jailbreak detection is always on. A separate jailbreak attack filter watches for attempts to bypass or disable safety features. It can’t be turned off and is independent of the per-channel severity sliders.
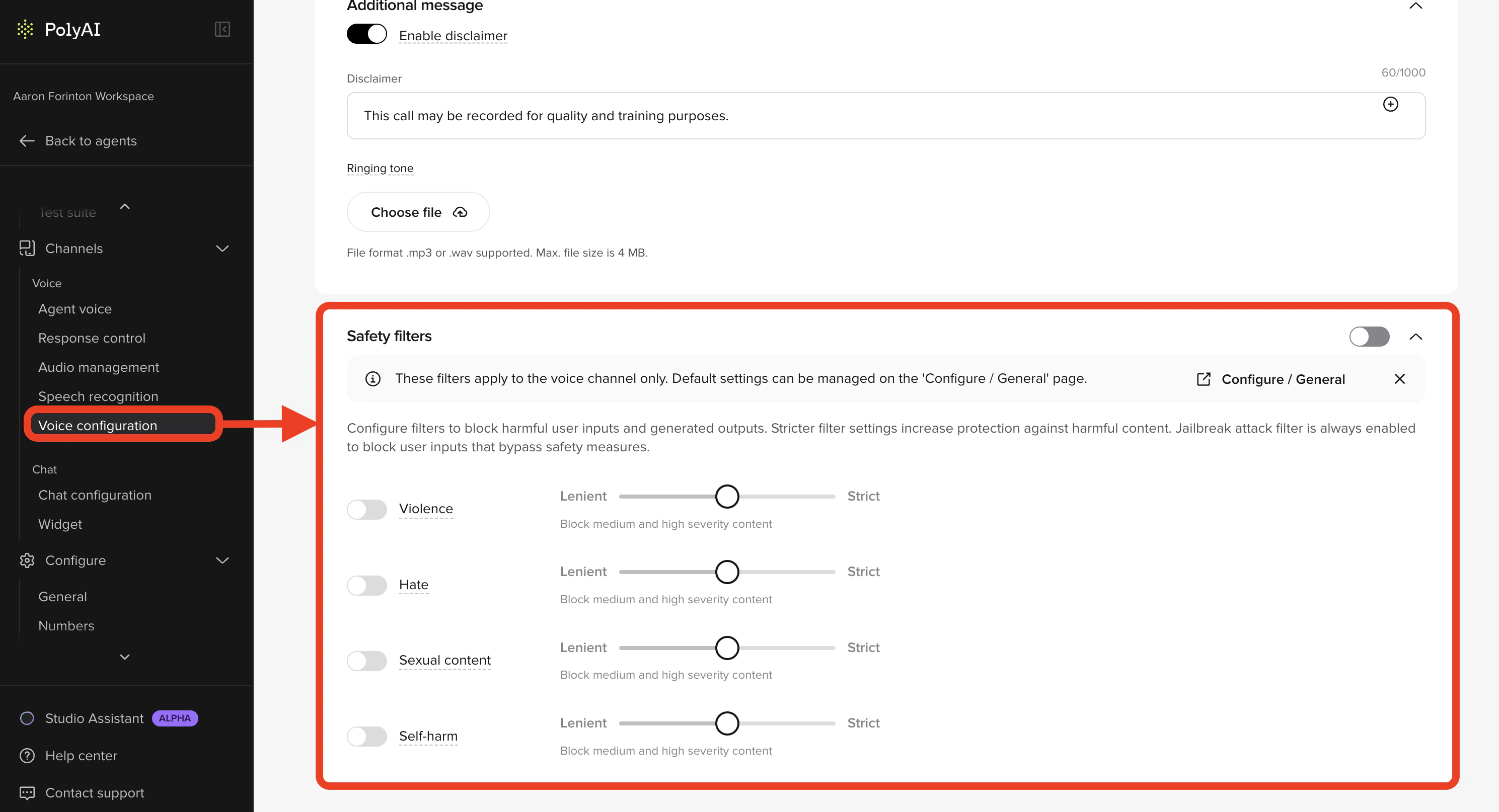
Project defaults vs. channel overrides
Safety filters are configured on a per-channel basis with project-wide defaults as a fallback.- Project defaults – set in Configure > General. Apply to any channel that does not have its own overrides enabled.
- Voice channel – override in Channels > Voice > Voice configuration. See Voice configuration → Safety filters.
- Chat channel – override in Channels > Chat > Chat configuration. See Chat configuration → Safety filters.
Edit filters
- Open Configure > General and find the Safety filter defaults section to set the project-wide baseline.
- To override for a specific channel, open the channel’s configuration page (Channels > Voice or Channels > Chat), enable safety filters, and adjust the sliders.
- Save. Voice and project-level changes follow the standard environment branching; chat changes take effect immediately on save.
- Test with Chat with Agent or a sandbox phone number before promoting.
Monitor filter activity
Every filter trigger is recorded on the conversation. Monitor across conversations from the Safety dashboard:- Calls managed for risk – how often filters fired (count and percentage).
- Caller utterance category – breakdown by hate, sexual, violence, and self-harm.
- Caller utterance risk level – risk distribution of incoming messages.
- Distribution of flagged calls – trend over time.
Language support
Filters have been trained and tested in English, German, Japanese, Spanish, French, Italian, Portuguese, and Chinese. Other languages are supported but performance may vary – test thoroughly in your target language before going live.How safety filters fit with Guardrails
Safety filters and platform Guardrails protect different layers and are designed to run together:- Safety filters classify each input and output against hate, sexual, violence, and self-harm before/after the LLM. They block content at the model layer.
- Guardrails are prompt-level instructions that shape how the LLM responds – for example, refusing to disclose its identity or escalating on a crisis signal.
- Jailbreak detection (always-on filter) blocks malicious input upstream; the Jailbreak & Prompt Defence guardrail tells the LLM how to respond if anything slips through.
- Emergency & Crisis Escalation (a guardrail) catches conversational distress signals that the self-harm filter misses – for example, “I don’t want to be here anymore” said in a measured tone.
Best practices
- Test thoroughly – run your own tests to validate filter behavior against representative content from your domain.
- Don’t default to Strict – find the level that prevents harm without over-filtering legitimate calls. Over-filtering causes safe fallbacks that hurt CX.
- Be consistent across variants – when running A/B tests or multiple agents, keep filter levels aligned so reporting is comparable.
- Review flagged calls weekly – use the Safety dashboard to catch drift before it becomes a compliance issue.
Related pages
Guardrails
Platform-level prompt protections that run alongside safety filters.
Safety dashboard
Monitor flagged conversations and filter trigger trends.
Voice configuration
Per-channel filter overrides for voice.
Chat configuration
Per-channel filter overrides for chat.