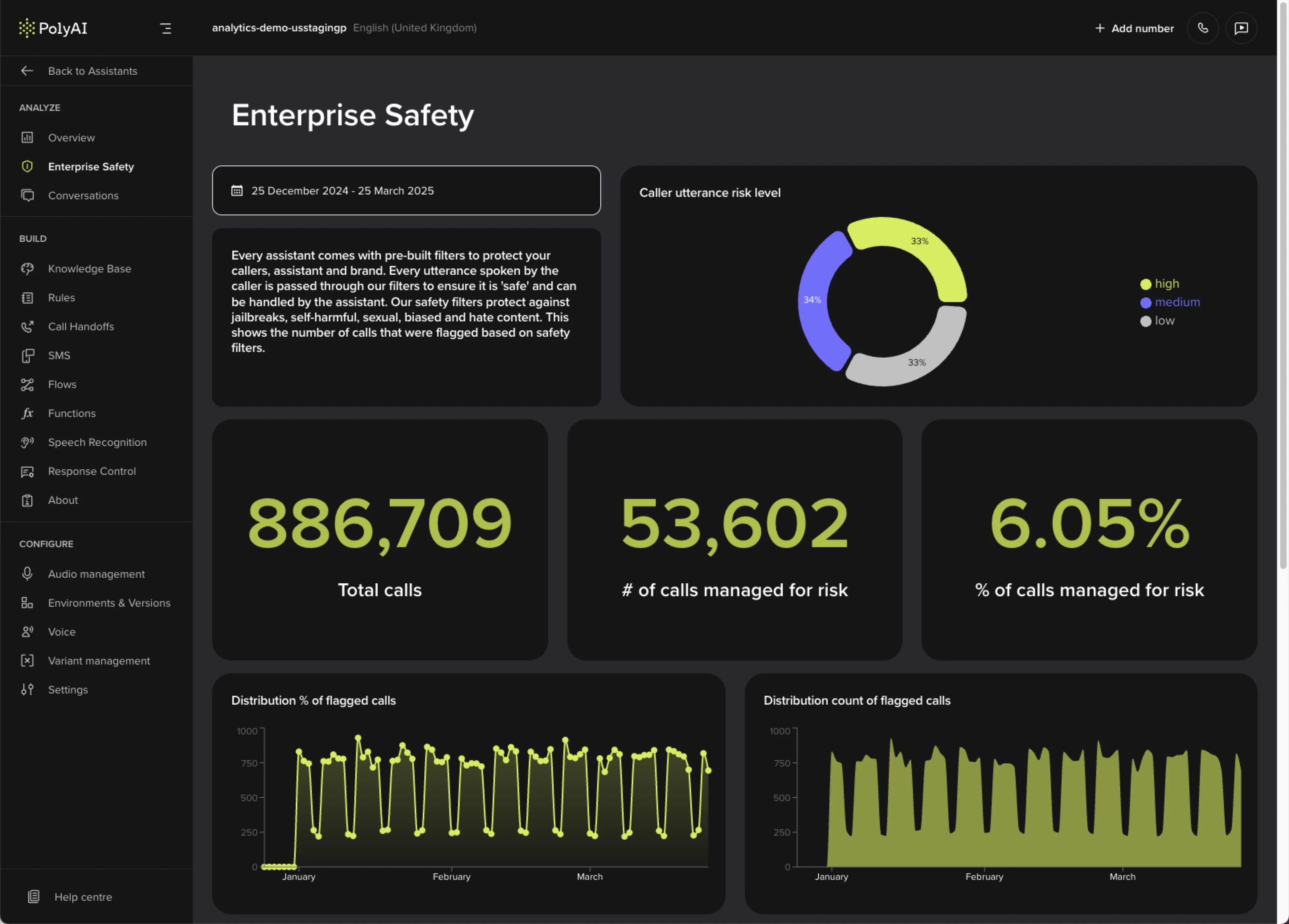
Metrics
Configuring filters
Safety filters are configured project-wide in Behavior and overridden per channel in Voice and Messaging. See Safety filters for the full reference – categories, severity levels, language support, and how filters fit with Guardrails.Related pages
Safety filters
Configure per-channel filter categories and severity levels.
Standard dashboard
Day-to-day performance monitoring: containment, call volume, and duration.
Conversation review
Inspect individual flagged conversations in full transcript view.