A/B testing (Beta)
A/B testing (Beta)
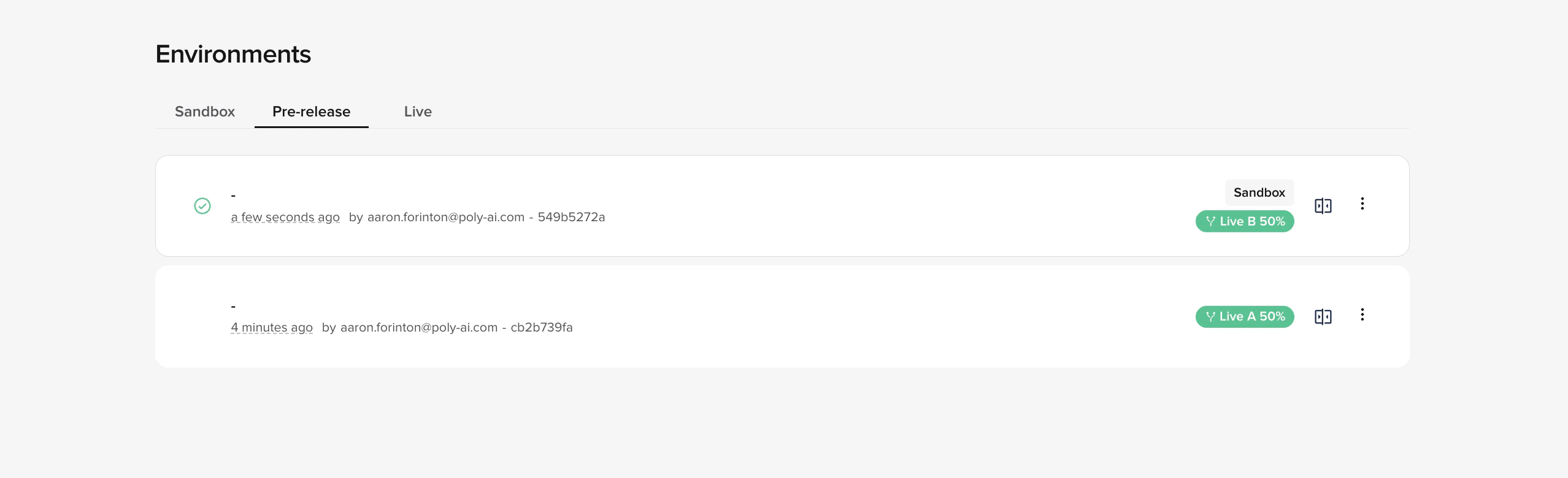
- Control vs. variant — the current Live version is the control (A); the version you promote from Pre-release is the variant (B).
- Configurable split — set the traffic split at test start, from 5/95 to 95/5 in 5% steps (defaults to 50/50). Calls are routed at the start of the conversation and stay on the assigned version for the whole call.
- Real metrics, side by side — both versions write to the same analytics tables tagged with their deployment version. Filter dashboards by deployed version to compare CSAT, containment, latency, handover rate, function errors, and anything else you already track.
- Safe guardrails on the pipeline — only one active test per project; promotions to Live and rollbacks of the control are blocked while a test is running.
- End on your terms — pick a winner when you have enough data; the chosen version is promoted to Live immediately and the test appears in Live Version History.
ab_tests feature flag — ask your PolyAI representative to enable it for your project.See A/B testing for the full walkthrough.Platform Guardrails
Platform Guardrails
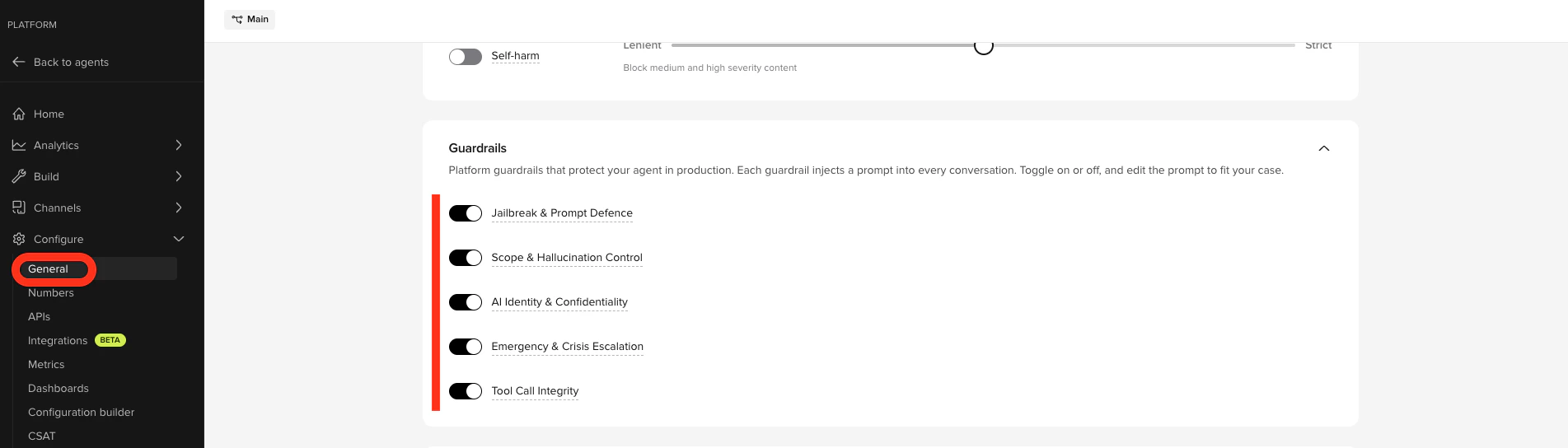
- Jailbreak & Prompt Defence – blocks attempts to extract instructions, override behavior, or impersonate a different AI system.
- Scope & Hallucination Control – restricts the agent to its knowledge base and prevents fabrication of phone numbers, prices, or policies.
- AI Identity & Confidentiality – prevents disclosure of the underlying LLM, provider, or platform.
- Emergency & Crisis Escalation – escalates immediately on suicidal ideation, self-harm, threats, or medical emergencies. Catches conversational distress signals that content filters miss.
- Tool Call Integrity – stops the agent from speaking internal function or tool names aloud.