{qIdx + 1} {q.q}
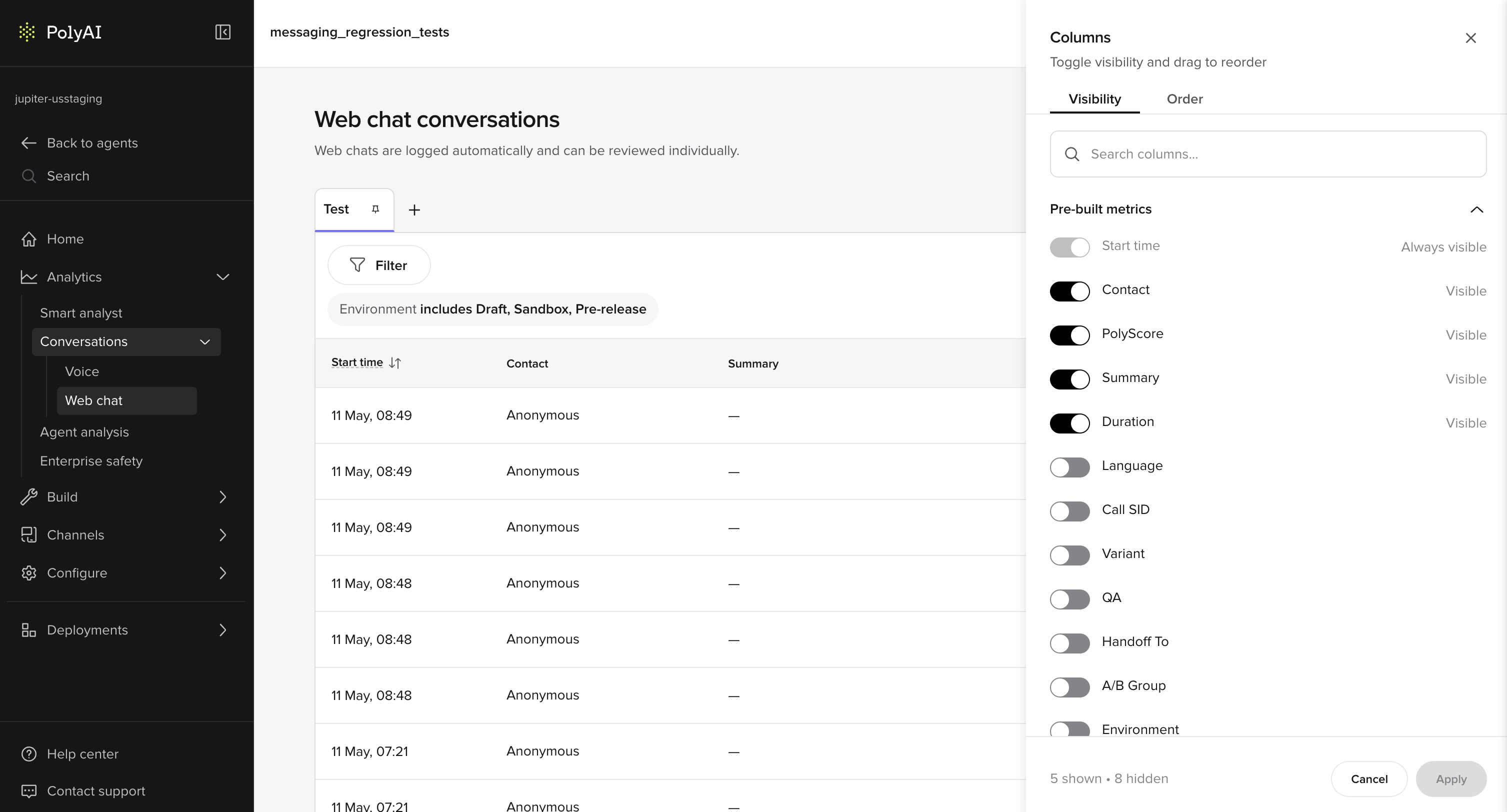 ## Comparative review patterns
At Level 2, you should rarely inspect a single conversation in isolation.
Common patterns:
* Same intent, different variants
* Same KB topic, different phrasing
* Same user request across Chat and Call
* Same flow before and after a KB change
Conversation Review supports this by exposing **environment, variant, and function data together**.
## Diagnosis layers (deep use)
Toggle diagnosis layers selectively. Each answers a different class of question.
### Topic citations (advanced)
At this level, topic citations are not just about *correct vs incorrect*.
Use them to detect:
* Topic competition
* Overly generic topic names
* Sample question leakage across intents
> Example:
> Three topics are cited repeatedly for "late checkout":
>
> * late\_checkout
> * checkout\_policy
> * general\_stay\_questions
>
> This indicates retrieval ambiguity. The fix is structural, not textual.
### Tool calls (advanced)
Tool call traces show **what the agent committed to doing**, not just what it said.
Inspect:
* Call order
* Conditional execution
* Parameters passed
* Calls that *should* have happened but didn't
> Example:
> The agent asks for SMS consent but never calls `start_sms_flow`.
>
> This usually indicates:
>
> * A missing action branch in the KB
> * A response control interrupting output
> * A rules conflict preventing execution
### Flows and steps
Flows expose **decision paths**.
Use them when:
* Multiple conditions exist
* Behavior depends on prior turns
* The agent appears to "jump" topics
> Example:
> A billing question enters a reservation flow.
>
> This is often caused by:
>
> * Early entity capture
> * Over-eager routing rules
> * Poorly scoped flow entry conditions
### Variants
Variants let you attribute behavior to configuration, not chance.
Use this layer to:
* Confirm A/B test intent
* Validate rollout sequencing
* Identify variant-specific failures
> Example:
> Variant A answers directly.
> Variant B always clarifies first.
>
> Conversation Review lets you confirm this per turn, not anecdotally.
### Entities
Entities are where ASR, NLU, and logic meet.
Inspect entities to:
* Confirm values were actually captured
* Detect silent failures (nulls)
* Spot hallucinated structure
> Example:
> User says "tomorrow morning"
>
> Entity captured: date = today
>
> This is not a KB issue – it's extraction or phrasing.
### Turn latency and interruptions
These layers reveal **experience quality**, not correctness.
Use them to:
* Identify responses that are too long for voice
* Detect places users consistently interrupt
* Tune pacing and verbosity
> Example:
> High interruption rate during policy explanations usually means the response is technically correct but poorly shaped for audio.
## Audio analysis (calls)
At Level 2, audio review is not optional.
Use split audio to:
* Isolate ASR failures
* Hear barge-in timing
* Compare spoken length vs transcript length
This often explains why "perfectly fine" text responses fail in voice.
## Annotations as a system, not notes
At this stage, annotations should be **patterned**, not occasional.
Use them to:
* Track recurring KB gaps
* Justify ASR tuning
* Support decisions to split or retire topics
> Example:
> Five "Missing topic" annotations around refunds in one day is enough evidence to create a dedicated refund topic.
Annotations turn subjective impressions into actionable signals.
## Check your understanding
## Comparative review patterns
At Level 2, you should rarely inspect a single conversation in isolation.
Common patterns:
* Same intent, different variants
* Same KB topic, different phrasing
* Same user request across Chat and Call
* Same flow before and after a KB change
Conversation Review supports this by exposing **environment, variant, and function data together**.
## Diagnosis layers (deep use)
Toggle diagnosis layers selectively. Each answers a different class of question.
### Topic citations (advanced)
At this level, topic citations are not just about *correct vs incorrect*.
Use them to detect:
* Topic competition
* Overly generic topic names
* Sample question leakage across intents
> Example:
> Three topics are cited repeatedly for "late checkout":
>
> * late\_checkout
> * checkout\_policy
> * general\_stay\_questions
>
> This indicates retrieval ambiguity. The fix is structural, not textual.
### Tool calls (advanced)
Tool call traces show **what the agent committed to doing**, not just what it said.
Inspect:
* Call order
* Conditional execution
* Parameters passed
* Calls that *should* have happened but didn't
> Example:
> The agent asks for SMS consent but never calls `start_sms_flow`.
>
> This usually indicates:
>
> * A missing action branch in the KB
> * A response control interrupting output
> * A rules conflict preventing execution
### Flows and steps
Flows expose **decision paths**.
Use them when:
* Multiple conditions exist
* Behavior depends on prior turns
* The agent appears to "jump" topics
> Example:
> A billing question enters a reservation flow.
>
> This is often caused by:
>
> * Early entity capture
> * Over-eager routing rules
> * Poorly scoped flow entry conditions
### Variants
Variants let you attribute behavior to configuration, not chance.
Use this layer to:
* Confirm A/B test intent
* Validate rollout sequencing
* Identify variant-specific failures
> Example:
> Variant A answers directly.
> Variant B always clarifies first.
>
> Conversation Review lets you confirm this per turn, not anecdotally.
### Entities
Entities are where ASR, NLU, and logic meet.
Inspect entities to:
* Confirm values were actually captured
* Detect silent failures (nulls)
* Spot hallucinated structure
> Example:
> User says "tomorrow morning"
>
> Entity captured: date = today
>
> This is not a KB issue – it's extraction or phrasing.
### Turn latency and interruptions
These layers reveal **experience quality**, not correctness.
Use them to:
* Identify responses that are too long for voice
* Detect places users consistently interrupt
* Tune pacing and verbosity
> Example:
> High interruption rate during policy explanations usually means the response is technically correct but poorly shaped for audio.
## Audio analysis (calls)
At Level 2, audio review is not optional.
Use split audio to:
* Isolate ASR failures
* Hear barge-in timing
* Compare spoken length vs transcript length
This often explains why "perfectly fine" text responses fail in voice.
## Annotations as a system, not notes
At this stage, annotations should be **patterned**, not occasional.
Use them to:
* Track recurring KB gaps
* Justify ASR tuning
* Support decisions to split or retire topics
> Example:
> Five "Missing topic" annotations around refunds in one day is enough evidence to create a dedicated refund topic.
Annotations turn subjective impressions into actionable signals.
## Check your understanding
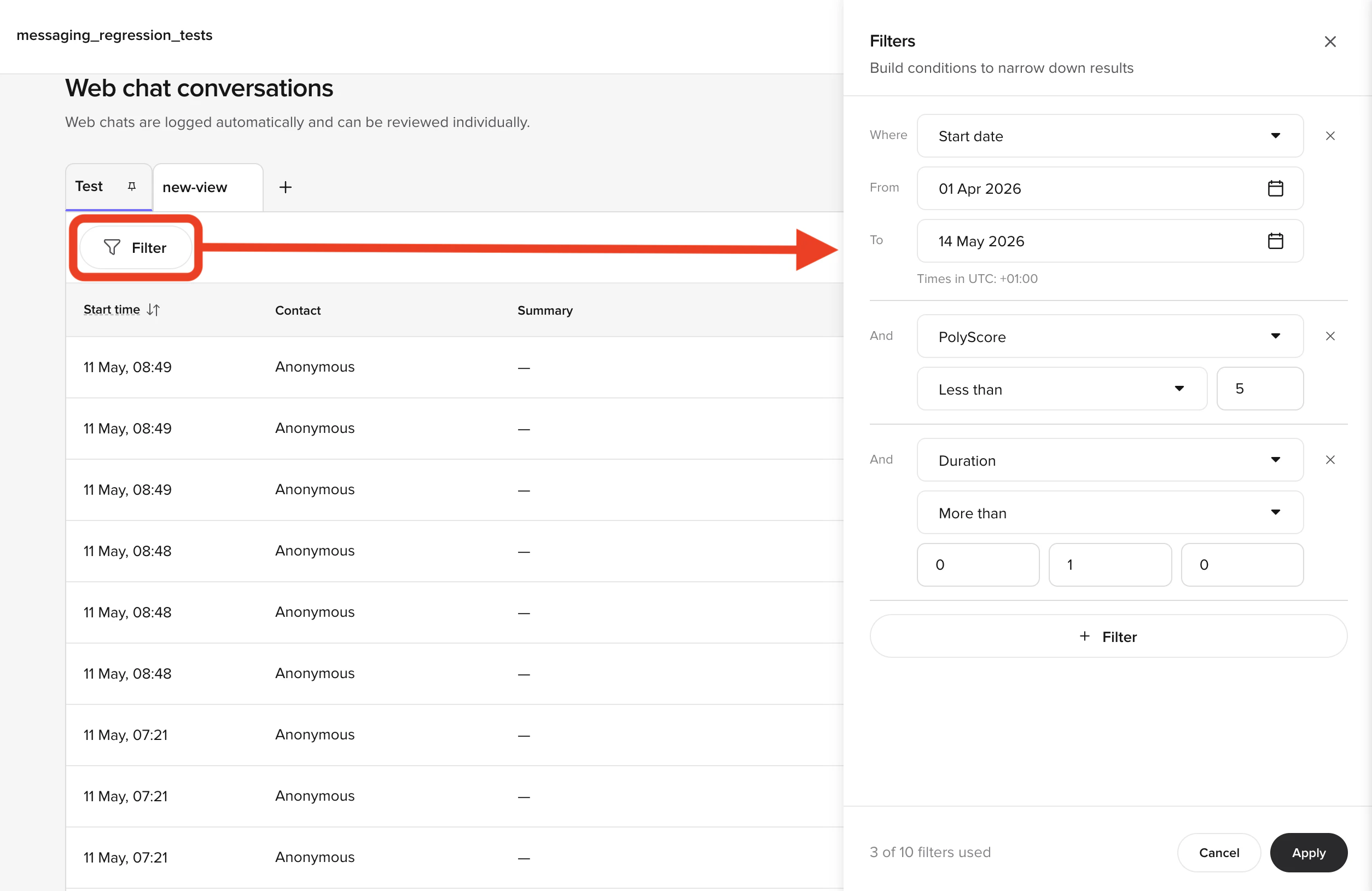
 ### QA metrics
The QA metric identifies which knowledge topic the agent used to answer each query:
* **Raven (voice)** – the LLM determines the QA metric directly by matching its response to the most relevant topic. This is accurate because the LLM has full context.
* **GPT-based agents (chat)** – the system encodes the user utterance, finds the closest topics by embedding similarity, generates a response, then matches the response back to topics. This can be less accurate when responses blend multiple topics.
A conversation can match more than one topic across turns. When that happens, the **QA** column in the conversations table shows every matched topic for that call, joined by commas (for example, `billing, handoff`), so you can see the full set of topics at a glance without opening each conversation. The same comma-joined format is used for any other custom metric that is logged multiple times on a single conversation.
### Using dashboards for improvement
A well-built dashboard tracks your key metrics (containment, transfer rate, call duration, authentication success) over time. Focus on:
1. **Containment trends** – are your improvements actually moving the number?
2. **Top queries** – what are users asking about most? Are there unhandled intents?
3. **Handoff reasons** – which reasons have the highest volume? Can you add flows or topics to reduce transfers?
For example, if "make an order" is a top query with high transfer rate, building an order troubleshooting flow could directly improve containment.
### QA metrics
The QA metric identifies which knowledge topic the agent used to answer each query:
* **Raven (voice)** – the LLM determines the QA metric directly by matching its response to the most relevant topic. This is accurate because the LLM has full context.
* **GPT-based agents (chat)** – the system encodes the user utterance, finds the closest topics by embedding similarity, generates a response, then matches the response back to topics. This can be less accurate when responses blend multiple topics.
A conversation can match more than one topic across turns. When that happens, the **QA** column in the conversations table shows every matched topic for that call, joined by commas (for example, `billing, handoff`), so you can see the full set of topics at a glance without opening each conversation. The same comma-joined format is used for any other custom metric that is logged multiple times on a single conversation.
### Using dashboards for improvement
A well-built dashboard tracks your key metrics (containment, transfer rate, call duration, authentication success) over time. Focus on:
1. **Containment trends** – are your improvements actually moving the number?
2. **Top queries** – what are users asking about most? Are there unhandled intents?
3. **Handoff reasons** – which reasons have the highest volume? Can you add flows or topics to reduce transfers?
For example, if "make an order" is a top query with high transfer rate, building an order troubleshooting flow could directly improve containment.